

Alluxio Updates Data Orchestration Platform To Let Apps Connect with Data Up to Five Times Faster 
Alluxio’s data orchestration offering is adding Structured Data Service to further deliver compute-optimized data. The update removes bottlenecks to how apps work with analytics and query engines.
by Vance McCarthy
Tags: Alluxio, analytics, apps, cloud, compute, data orchestration, Presto, query engines, storage,

CEO
"Alluxio separates compute from storage, and that simplifies and accelerates how enterprise teams work with distributed data-intensive workloads."
Architecture Summit
 Enterprise-Grade Integration Across Cloud and On-Premise
Enterprise-Grade Integration Across Cloud and On-PremiseAlluxio has updated its cloud-based data orchestration software to help architects and developers get more bang from their buck when working with analytics and query engines.
Alluxio 2.2. adds a set of Structured Data Service technologies, which will deliver compute-optimized data for such projects. The update removes many bottlenecks to how apps now work with data. It also provides developers easy ways to support advanced analytics and AI on remote data for hybrid and multi-cloud projects, according to Alluxio execs.
“Users aren’t always getting as much ROI as they might from using today’s analytics or query engines,” Alluxio CEO Steven Mih told IDN. “They often run into inefficient data formats and face performance challenges.” Issues can include difficult mappings or trouble with creating converted copies of the data, he noted.
These issues can occur because such engines consume structured data in different databases with “tables” consisting of “rows” and “columns”, rather than “offset” and “length” in files or objects. This can happen with many popular engines, including Presto, Apache Spark SQL or Apache Hive.
“The Alluxio cloud-based data orchestration platform, removes many of these issues by providing a layer that separates storage and compute,” Mih told IDN. In specific, Alluxio approach eliminates data duplication, brings speed and agility to big data and AI workloads, lets companies move to newer data storage solutions -- and cuts costs for it all, Mih said.
Benefits of Alluxio Structured Data Service with Data Orchestration
With the addition of Structured Data Service, Alluxio 2.2 exposes data so it can be more effectively accessed by SQL engines. In turn, this lets developers more easily connect their apps to different catalogs for access to structured data -- independent of the storage solution or format, Mih said.
“Alluxio can now perform just-in-time data transforms of data and boost performance by making data compute-optimized” for Presto and similar engines for analytics and queries, added Aseem Rastogi, Alluxio’s vice president of engineering.
Not surprisingly, this means apps can get to the data they need a lot quicker -- up to five times faster, Mih added. And when apps can more quickly and smoothly connect to the data they need, app performance also improves.
Alluxio’s internal tests have shown an “increase in query performance by over 2.5x,” the company said, “while results depend on the specific formats and workloads.”
“Alluxio runs with the compute engines and makes all that happen. Compute engines are attached to Alluxio and mount the data sources. With a simple command, we create the compute-optimized versions, so we just do it for them,” Mih told IDN. “Presto [and similar engines] can now boost performance, independent of data format or storage capacity That’s because Alluxio’s technology separates compute from storage,” Mih added.
The Alluxio data orchestration layer also simplifies and accelerates how enterprise teams work with distributed data-intensive workloads – across on-prem, cloud and multi-clouds, Rastogi noted.
“We’re not making a new copy. We are bringing the data to the compute Always designed to orchestrate data to the compute and mounts different data sources and makes it local.”
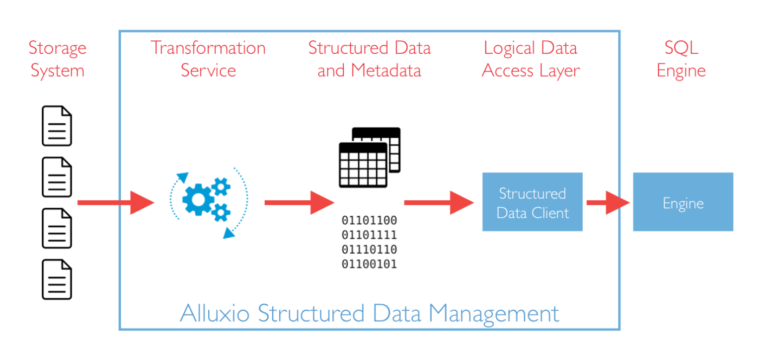
Drill-Down into Alluxio’s Structured Data Service
Alluxio Structured Data Service provides a block-level read/write caching engine to enable a range of analytic engines to connect to various storage systems, including S3 and HDFS. Presto can query files stored in Alluxio through the Hive connector.
Other Alluxio 2.2 capabilities and services include:
Presto Connector for Alluxio – The new Presto connector for Alluxio allows easy integration and configuration of Alluxio with Presto. Alluxio’s data orchestration layer provides a block-level read/write caching engine for Presto connecting to a variety of disparate storage systems, including S3 and HDFS. Presto can query files stored in Alluxio through the Hive connector.
Catalog Service – This service manages the metadata of structured data in the system. It is responsible for all the database, table, and schema information, as well as the location of all the stored data. With Catalog Service, users no longer need to change any table locations in the Hive metastore, or to restart or reconfigure any Hive services.
The Catalog Service enables schema-aware optimizations for any type of structured data. For example, once the Hive metastore is attached to Alluxio’s Catalog Service, the service will automatically mount the appropriate table locations and serve the table metadata with the Alluxio locations.
Transformation Service – This service transforms data into a compute-optimized representation of the data and promotes physical data independence from the storage-optimized format. Alluxio makes three (3) types of transformations available for tables:
- Coalesce enables the data to be combined into fewer files. This offers advantages because a large number of files in a table are inefficient for SQL engines to process
- Format conversion, which includes format conversion from CSV to Parquet, and
- Sorting
Alluxio founder and CTO Haoyuan Li, described in detail how Alluxio’s added capabilities work together to deliver compute-optimized, just-in-time data transforms for OLAP engines, such as Presto and Apache Spark – and retain independence of the storage format.
“These schema-aware optimizations are made possible with the new Alluxio Catalog Service which abstracts the widely-used Apache Hive Metastore. [S]o regardless of how the data was initially stored – CSV and text formatted files, for example – the data is now transformed into the generally recognized compute-optimized parquet format. Almost every organization has a surprising amount of data in CSV or other text formats and this removes the manual work to make that data more usable.
A second type of transformation will coalesce many smaller files, enabling the data to be combined into fewer files, which is more efficient to process for SQL engines.
And yet a third type of transformation is for sorting, enabling table columns to be sorted adding to the efficiency of queries, newly available in our Enterprise Edition.
Founding engineer Gene Pang also detailed in a blog post how the latest Alluxio upgrades represent a new approach to deliver more frictionless unified data access.
Today, many users deploy Alluxio in analytics or AI platforms to provide unified data access while transparently caching the relevant data for accelerated data IO. No matter the computation framework being used, Alluxio can provide the abstraction on files, directories, and objects in a logical “Alluxio File System.”
Files and directories are the standard means for a filesystem to arrange and access data, but this format is not always compatible with various analytics engines. For compute frameworks such as Presto, Apache Spark SQL, or Apache Hive, the desired data format is represented as a table, consisting of rows and columns. This disparity is analogous to a conversation between two people who speak different languages; in order for one to understand the other, there must always be a translator present. This inefficiency grows as the data scale increases since each piece of information retrieved must first be converted before it is consumable and vice versa when storing computed information.
Our goal is to deliver physical data independence, where the logical access of data by the SQL engines is independent from the physical format of the stored data. Since Alluxio is the ecosystem layer between compute and storage, Alluxio is in a great position to bridge the gap between SQL engines and file or object-based storage systems to enable physical data independence.
One analyst has a positive outlook on Alluxio and its architecture.
“We can thank Kubernetes for distributed compute; and Alluxio for distributed data. The combination of these technologies offers tremendous promise for our data-driven hybrid and multicloud future,” said Eric Kavanagh, CEO of Bloor Group in a statement.
Alluxio 2.2 Community and Enterprise Edition with Structured Data Service are generally available for download.
Related:
- Cloud Migration Isn’t Going Away: 4 Warning Signs a Change is Needed
- Qumulo Latest Driver Improves Storage Management of Kubernetes Apps and Workflows
- Cloudflare Unifies Email Security and Zero Trust with Acquisition of Area 1 Security
- 5 Ways Companies Can Protect Themselves When AWS Goes Down
- Astadia Joins the AWS Mainframe Modernization Service
All rights reserved © 2025 Enterprise Integration News, Inc.