

Zilliz Improves AI-Optimized Vector Databases with More Speed, Scale and Ease of Use 
In 2025, the vector database, a foundational piece of an AI infrastructure, is going to provide more scale, more speed and be easier to use, thanks to upgrades from Zilliz. IDN speaks with CEO and Founder Charles Xie.
by John Hutchinson
Tags: AI, algorithms, automation, cloud, Milvus, scale, vector database, Zilliz,

CEO and Founder
"We see the future for vector database and unstructured data processing is three directions. It will get bigger and faster and cheaper."

In 2025, the vector database, a foundational piece of an AI infrastructure, is going to provide more scale, more speed and be easier to use, thanks to upgrades from Zilliz.
Zilliz is a leading vector database company, founded by the engineers who created the popular
Milvus open source vector database. Updates are available this month for the Zilliz Cloud fully managed vector database and Milvus. IDN spoke about the updates with Zilliz CEO and Founder Charles Xie.
As companies continue to invest in their AI Stack of technologies, a key consideration will be how they add support for unstructured data, of various types including text, images, video and more, Xie told IDN. With the latest Zilliz Cloud updates, Xie and his team are delivering several improvements for how companies use, store, manage and optimize their unstructured data for AI.
“As companies scale up similarity search for recommendation systems, RAG, and image retrieval, they face a choice between overprovisioning hardware or spending months tuning vector indexes. The vector database system is a database system to store, to index and to manage and provide highly efficient data retrieval over unstructured data. More than 90 percent of what data exists today is unstructured data,” Xie told IDN.
“So, there needs to be another purpose-built database system to store, to index, to manage, and to retrieve all this unstructured data in a very efficient way.”
Xie highlighted several keys ways Zilliz Cloud is filing these needs, and where Xie says Zilliz investments will continue in the new year.
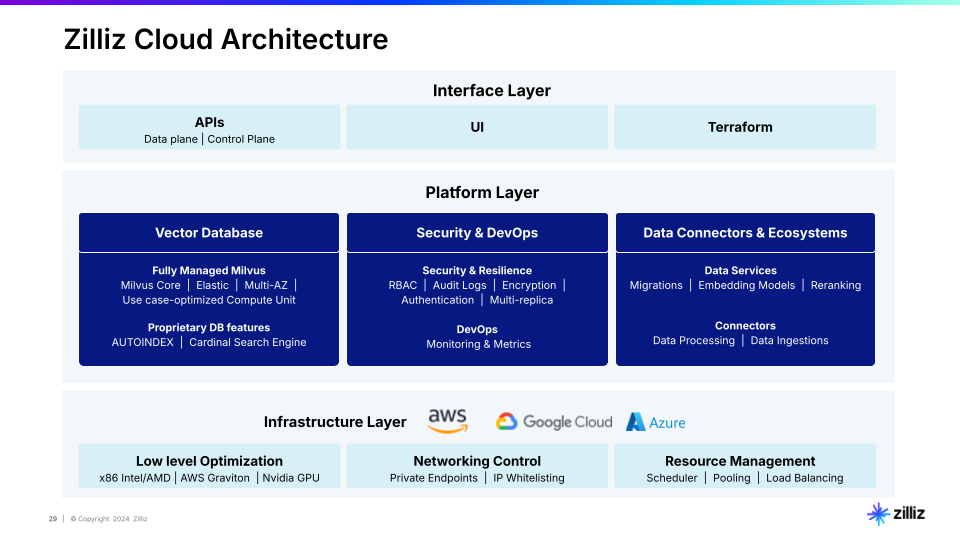
Superior AI-powered search. Zilliz Cloud goes beyond simple vector search to combine multiple modes, which delivers a wide range of advanced operations such as single-vector search, hybrid search with multi-vector fields, even filtered search using scalar fields to refine results and grouping search to ensure diverse results.
The Zilliz architecture can combine dense and sparse vectors, which improves outcomes across different data types for better AI-optimized results.
To illustrate how AI outcomes benefit from leveraging these multiple modalities of search, Xie shares examples of how dense search and sparse search work together.
Dense vectors are like a detailed painting where every spot on the canvas has color - they pack a lot of information into every part of the vector. When used for searching text, these dense vectors are good at understanding the meaning of what you're looking for.
Sparse vectors, on the other hand, are like a mostly empty canvas with just a few specific marks - most of the vector is filled with zeros, and only a few positions have actual values. Think of it like a highlighter marking just the important words in a document. This makes them very efficient to store and search, and they're great at finding exact matches. For example, if you search for “Charles Xie birth date," it will specifically look for documents containing those exact terms, which can be more precise than dense vectors when you need exact matches.
AutoIndex. The addition of an AutoIndex capability to Zilliz Coud means “zero manual index tuning” Xie told IDN. This is largely thanks to a newly designed ”intelligent system that automatically selects the best search strategy based on customers’ data and hardware setup, eliminating the complexity of manual configuration without sacrificing optimal search performance,” he added.
Xie highlighted the many cost and time-saving benefits of Zilliz Cloud’s auto-indexing to both AI deployments and outcomes
A vector database and administrators spend like probably more than two weeks, probably like several months to, to learn what to do And every time you change your usage pattern, every time you have a new or different workload, you may have to tune again. So, you have to keep doing it, this is very costly and it's a burden to most of the customers.
What we found out is that like a database system we know that our database system is very, very complex. So, so that's why traditional database company like Oracle, they need a DBA, they need a database administrator to do this fine tuning, to set out to do configurations and set up all these parameters.
But with AutoIndex, we are providing autonomous driving mode for the vector database. it's tuned to your workload, to your usage pattern, and then you can, you can get the best performance, out of the box it's all pre set it by machine learning algorithm by AI. Because a vector database is trying to manage this high dimensional data. So, which means that there are a lot of parameters to configurate.
Algorithm optimizer. Zilliz Cloud also embeds advanced algorithms to optimize for hardware performance and data management. These include unified IVF-based and graph-based approaches, engineering solutions such as specialized memory allocation and multi-threading for real-world performance, according to Xie.
He explained how these deliver high-performance vector search through several layers of optimization:
“In the past, almost all this vector database solution they need to put all the data in pure memory, which is going to be very, very costly and very, very efficient. So we can now put all this data in memory in our local disk and as well in cloud object store,“ Xie told IDN. This will dramatically reduce the cost of storage.”
So our strategy is we can accommodate more data and dramatically reduce the total cost of ownership. With hierarch storage, we can reduce the cost of vector data database for more than 50 times. Now we can store a lot of most of the data in object store, we can store most of the data in local disk. Object store is 100 times cheaper than memory and local disk is 10 times cheaper than memory.
“The other thing we've done is tons of optimization to make sure that our execution engine can run very efficiently on modern processors,” Xie said. These include modern GPUs as well as CPUs from ARM, Intel and AMD. Zilliz Cloud is also optimizing for AWS infrastructure. “We've done tons of collaboration and heavy lifting” to make sure we can fully utilize the potential of today’s processors.
Zilliz Updates Milvus Open Source Vector Database
Zilliz also released the latest upgrade to the Milvus open source vector database in December.
Milvus 2.5 aims to let developers build more powerful and efficient search applications with less complexity. Among the additions are:
- Built-in Full-Text Search: Sparse-BM25 integration, enabling powerful text processing capabilities without requiring pre-generated vector embeddings. This is a game-changer for combining semantic search with keyword precision.
- Enhanced Text Filtering: New text match capability leverages Tantivy's analyzers for precise natural language matching, perfect for combining with vector similarity search.
- Bitmap Index: Introducing a new indexing system that significantly accelerates filtering on low-cardinality fields, improving query performance for filtered searches.
- Improved Data Management: Added support for nullable properties and default values in scalar fields, providing greater flexibility in data handling.
“The data space will get hotter and hotter in the next few years. The data volume is going to increase dramatically. And it's going to increase exponentially.” Xie said.
He further explained why vector data technologies will be a core technology to help AI adopting companies deal with these requirements.
“We see the future for vector database and unstructured data processing is three directions. It will get bigger and faster and cheaper,” Xie told IDN. “We are going to process more and more unstructured data. In the next five, five or 10 years, there's going to be 10%, 20%, 30 percent of unstructured data being processed.
Related:
- SolarWinds Brings “Resilience’ to IT Ops for Agentic AI and Autonomous Operations
- Tray Enterprise-Class AI Platform Casts Light on “Shadow MCP” and Controls “AI Sprawl”
- Xano 2.0 Updates Production Grade Backend for AI, Apps To Solve "Vibe Coding Trap"
- Ai4 2025 Vegas Wrap-Up: What Enterprises Need to Know About Emerging AI Solutions
- Boomi Agentstudio Looks To Deliver Full-Featured Management Platform for AI Agents
All rights reserved © 2025 Enterprise Integration News, Inc.