

Matillion Adds No-Code, Automation To Speed Delivery of CDC and Batch Data Pipelines 
Matillion is simplify data ingestion with no code and automation upgrades. IDN talks with Paul Johnson about Matillion Data Loader 2.0 for batch and change data capture pipelines.
by Vance McCarthy
Tags: batch CDC, data loading, ETL, integration, Matillion, no code,

director of product management
"No-code shouldn't be conflated with low sophistication. Matillion solves very complex problems for some of the biggest organizations in the world."
 Integration Powers Digital Transformation for APIs, Apps, Data & Cloud
Integration Powers Digital Transformation for APIs, Apps, Data & CloudMatillion is adding no-code and automation features to its popular data loader to help enterprises speed up and simplify batch and real-time CDC pipelines.
Matillion Data Loader 2.0 will let users build batch and streaming CDC pipelines in minutes -- without worrying about coding or infrastructure. Further, Matillion's approach offers a single unified UI experience and tools to work across batch loading and real-time.
Matillion's offering comes as enterprises are looking for faster delivery of analytics and data to help address growing challenges with data extraction and data integration, according to Paul Johnson, Matillion's director of product management.
"Creating new data pipelines is a complex and time-intensive task. Data teams report wasting more than half of their time (57%) on data migration and maintenance," Johnson said. He added that these delays can be caused by slow cloud migrations, limited legacy integration tools and time-consuming hand-coding of pipelines (which can also be error-prone).
According to Matillion, the need for faster and more agile data pipelines is proportional to the variety of a company's data sources. Note this eye-popping state of affairs from a recent Matillion blog post:
The average enterprise uses more than 400 different data sources in their analytics programs, and the top 20 percent of enterprises use more than 1,000. The diversity of data is also expanding and now includes a wide variety of types such as transaction data, logs, IoT, social media, audio/video, geospatial data, and many more. SaaS applications are also coming into the enterprise at an alarming rate.
Aside from no-code and automation, Matillion Data Loader 2.0 also adds:
- CDC capabilities to capture and replicate all change events in near real time to create an immutable history of all change events
- An intuitive, wizard-based user interface to save time and effort
- A hybrid SaaS architecture to give enterprises control of high-security pipelines
- Ability to monitor batch and CDC pipeline activities from a single dashboard
- Log-based, queryable historic change logs to support modern use cases (e.g., AI/ML model training, fraud detection, etc.)
- Predictable usage-pricing
- Deep integration into Matillion ETL
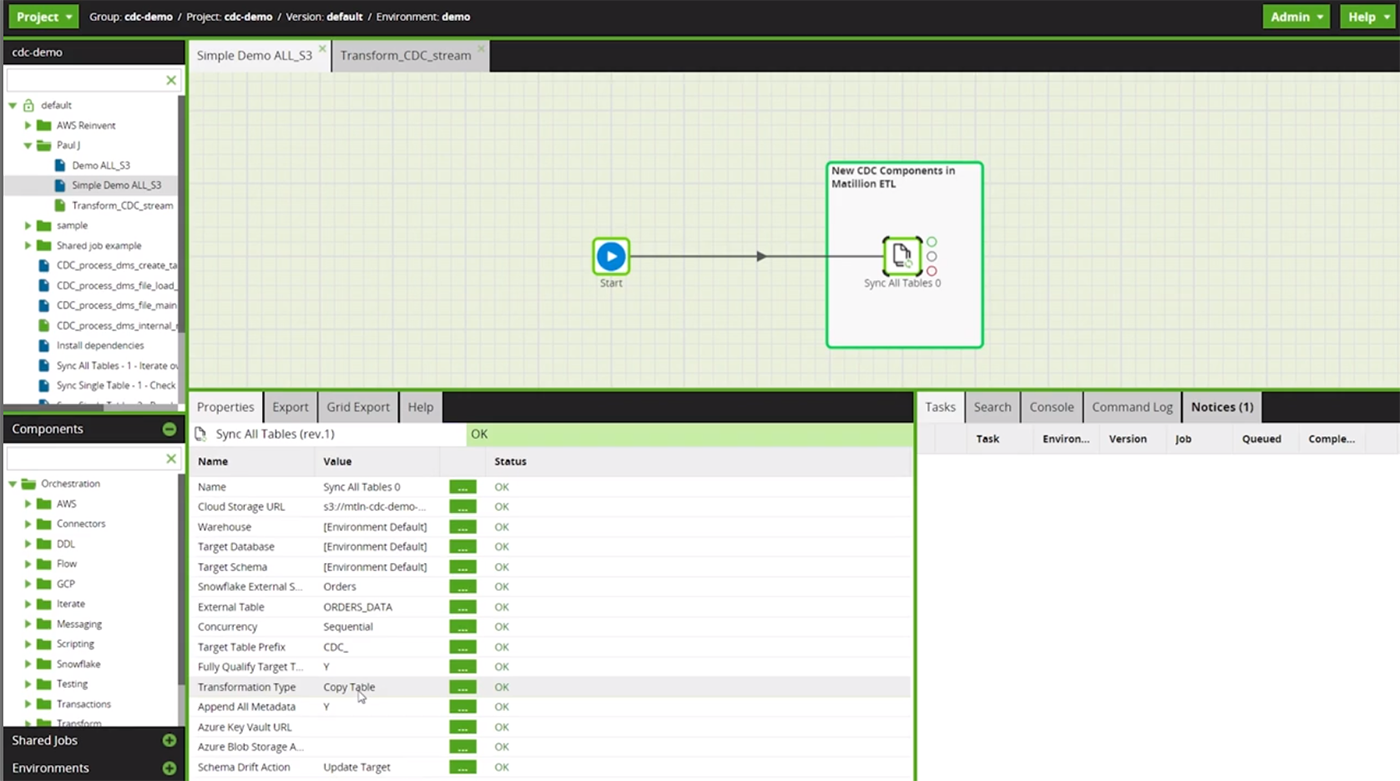
Matllion Data Loader 2.0's Support for No Code Pipelines
The Matillion Data Loader 2.0 lets a broad range of users quickly assemble "no-code" data pipelines. Matillion's approach to no-code ETL provides a large set of preconfigured, no-code integrations to data sources, Johnson said.
Matillion Data Loader 2.0 offers data mapping and lineage capabilities, visual drag and drop interfaces for building data pipelines, support for data transformations, automation and orchestration of workflows.
In fact, Matillion Data Loader 2.0 combines no-code with an intuitive UI and easy-to-use wizard configurations. As a result, users can build batch and CDC pipelines in minutes -- without SQL or coding, Johnson added.
No-code shouldn't be conflated with low sophistication. Matillion solves very complex problems for some of the biggest organizations in the world.
The Matillion Data Loader pipeline consists of a source and destination. To create a production-quality data pipeline, customers simply need to provide credentials to securely connect to the source and destination and select what data they want to move. Matillion Data Loader handles all of the integration, data loading and complex transformation, such as adaptive schema drift.
Matillion’s underlying data loader architecture aims to enable multiple users to meet varied use cases, he said.
Although anyone can use the product, what you do with the data once it's loaded requires specialist skills (e.g., data modeling, data warehousing and data visualization).
Our users are typically highly-skilled knowledge workers such as data analysts, data engineers, analytics engineers and other similar roles.
Data pipelines can be deployed and customized in a variety of different ways.
Security-conscious customers may opt for a hybrid architecture pipeline where the data movement runs in the customer environment behind the customer's own firewall, but all of the configuration is done in the SaaS application. In terms of frequency, batch-based pipelines can be scheduled to run every five minutes or every five days — and anywhere in between and beyond. In the case of CDC pipelines, they are near real-time and are always looking for changes as they happen.
To support such flexibility, Matllion Data Loader 2.0 offers a large inventory of pre-built, out-of-the-box data connectors that let users make no-code connections to many popular applications and databases.
Matillion also sports a "Create Your Own Connector framework" for custom user cases to let users build custom connectors to any REST API source system.
Matillion Data Loader 2.0 also manages these connector APIs so that customers can be sure integrations are always up to date with outside sources/targets.
We have a dedicated Connectors Team here that is always monitoring the latest changes to APIs and ensuring that the updates are pushed into the product before a breaking change happens.
Sometimes, not every change is documented, so we run daily tests on every connector we have to make sure they are all in working order. And if anything does stop working, we are the first to know and we mobilize our Incident Management Team to get fixes out to customers.
A recent blog post describes the Matillion Data Loader's approach to no/code/low code this way:
No-code solutions are available for many business tools today from databases such as Airtable and integration tools such as Zapier.
When it comes to ETL, it's obvious that companies need data connectors to a large number of different data sources, from on-premises databases to SaaS applications to file systems, to get their data into Snowflake. With so many different data sources, connecting to all of the sources, loading the data, and transforming it can be very time-consuming, with many companies using bespoke coding to customize these connectors and workflows. [It] turns out that these same outcomes can be accomplished with no-code and low-code solutions.
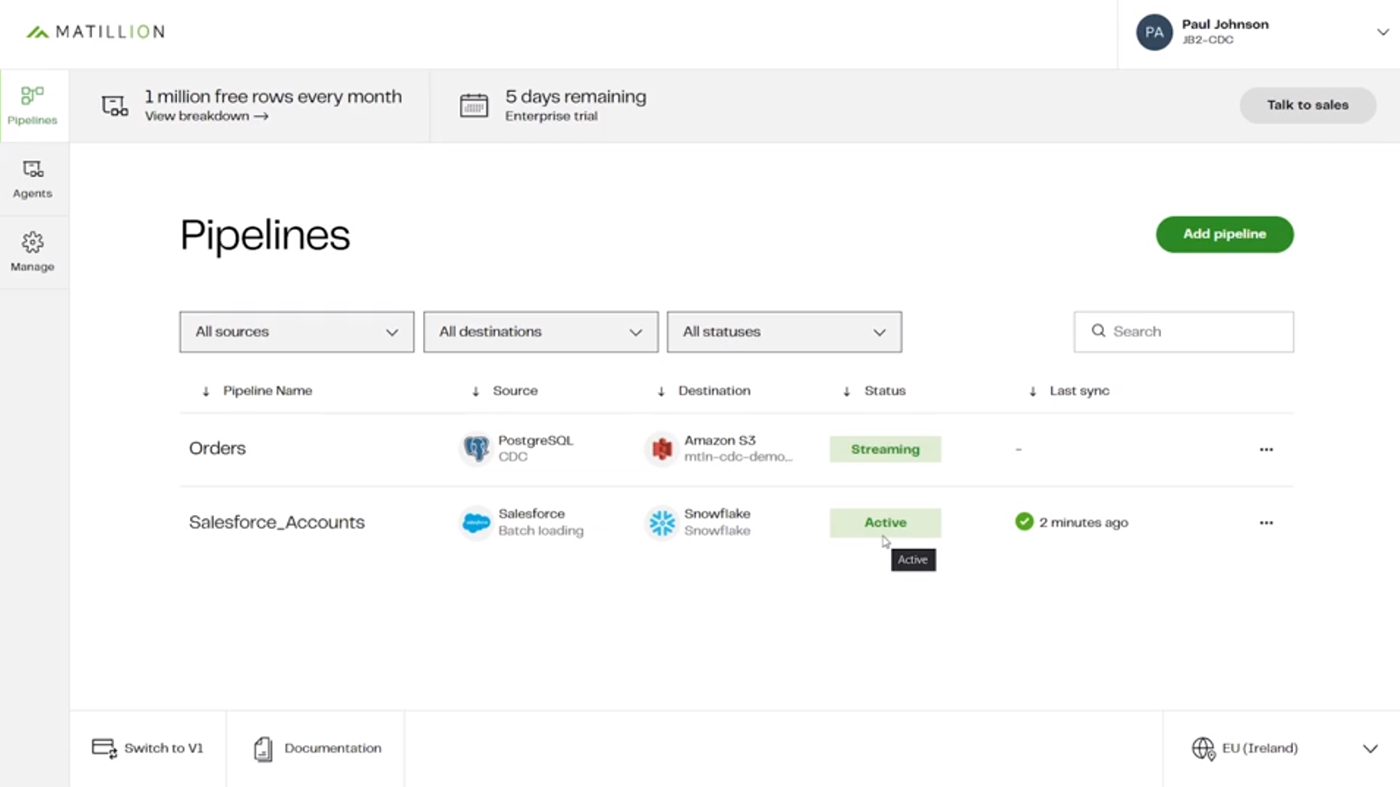
Matillion's Focus on Automatic' Schema Drift' Correction
The Matillion Data Loader 2.0 also provides what the company calls "automatic schema drift correction," which keeps source and destination data stores in sync.
Matillion describes the technology and its benefits this way:
Schema Drift occurs when your data source changes its metadata. On the fly, fields, columns, and types can be added, removed, or changed. If you don't account for schema drift, your data flow becomes vulnerable to changes in the upstream data source.
Matillion Data Loader pipelines can easily adapt to these schema changes and propagate them to the destination, without assistance from IT or the need to code.
These "self-healing" pipelines not only save time, they significantly reduce the number of job failures and delays due to schema drift. Users can ensure that data continues to flow, uninterrupted, from source to target.
This automated support to Schema Drift feature is "one of the biggest productivity boosts for customers," Johnson told IDN.
"Matillion Data Loader handles things like proper data type mapping from one system to another, or dealing with what happens when that data type is suddenly changed and everything needs to be updated downstream," he added. "This type of work tends to be time-consuming and error-prone when done manually."
Matillion's support for "hybrid cloud data pipelines" will also help companies support data pipelines for both on-prem and cloud data, Johnson added.
The concept of hybrid cloud data pipelines is currently available for CDC [Change Data Capture] and will be available for batch pipelines this year.
This means the actual compute resource that handles the data movement (we call them "agents") can be deployed into a customer's private cloud or on-prem data center. The Matillion SaaS platform sends instructions to the agent regarding the source and destination within the pipeline and where to get credentials to access the data, and the agent handles the movement of data so it stays within a specific network and geographical location.
Faster, Simpler Data Loaders Support for Business Outcomes
Matillion Data Loader 2.0 is also designed to help deliver business benefits quickly, according to company executives.
"Customers are able to move data within minutes of signing up," Johnson said.
Further, Ciaran Dynes, Matillion's chief product officer, added, "Using data at speed and at scale is a huge differentiator for enterprises. The ability to bring analytics-ready data to more people in the business while maintaining security and governance reduces friction and opens up the door to new insights."
Matillion is built on native integrations to cloud data platforms such as Snowflake, Delta Lake on Databricks, Amazon Redshift, Google BigQuery, and Microsoft Azure Synapse to enable new levels of efficiency and productivity across any organization.
Matillion Data Loader 2.0 is available today at dataloader.matillion.com/register.
Related:
- The Critical Integration Miss: Continuous Exploration
- Survey: 92% of Enterprises Working on, Planning App Modernization
- Tray.io Low-Code Integration, Automation Updates Drive Enterprise Hyperautomation
- Tray.io 'Embedded iPaaS' Empowers SaaS, ISVs via Low-Code, Automated Integrations
- API Management vs. Service Mesh: The Choice Doesn’t Have to Be Yours
All rights reserved © 2025 Enterprise Integration News, Inc.