

SingleStore Speeds ETL to Cloud via Native Integration with AWS Glue 
SingleStore is offering native support and integration with AWS Glue’s data prep service.
IDN talks with SingleStore’s Jordan Tigani about how the new capability makes it easier to perform ETL jobs – and even clean, enrich and normalize data.
by Vance McCarthy
Tags: SingleStore Speeds ETL to Cloud via Native Integration with AWS Glue,

chief product officer
"After a couple of clicks – developers can immediately start developing ETL routines instead of worrying about how to integrate [AWS] Glue and SingleStore libraries."

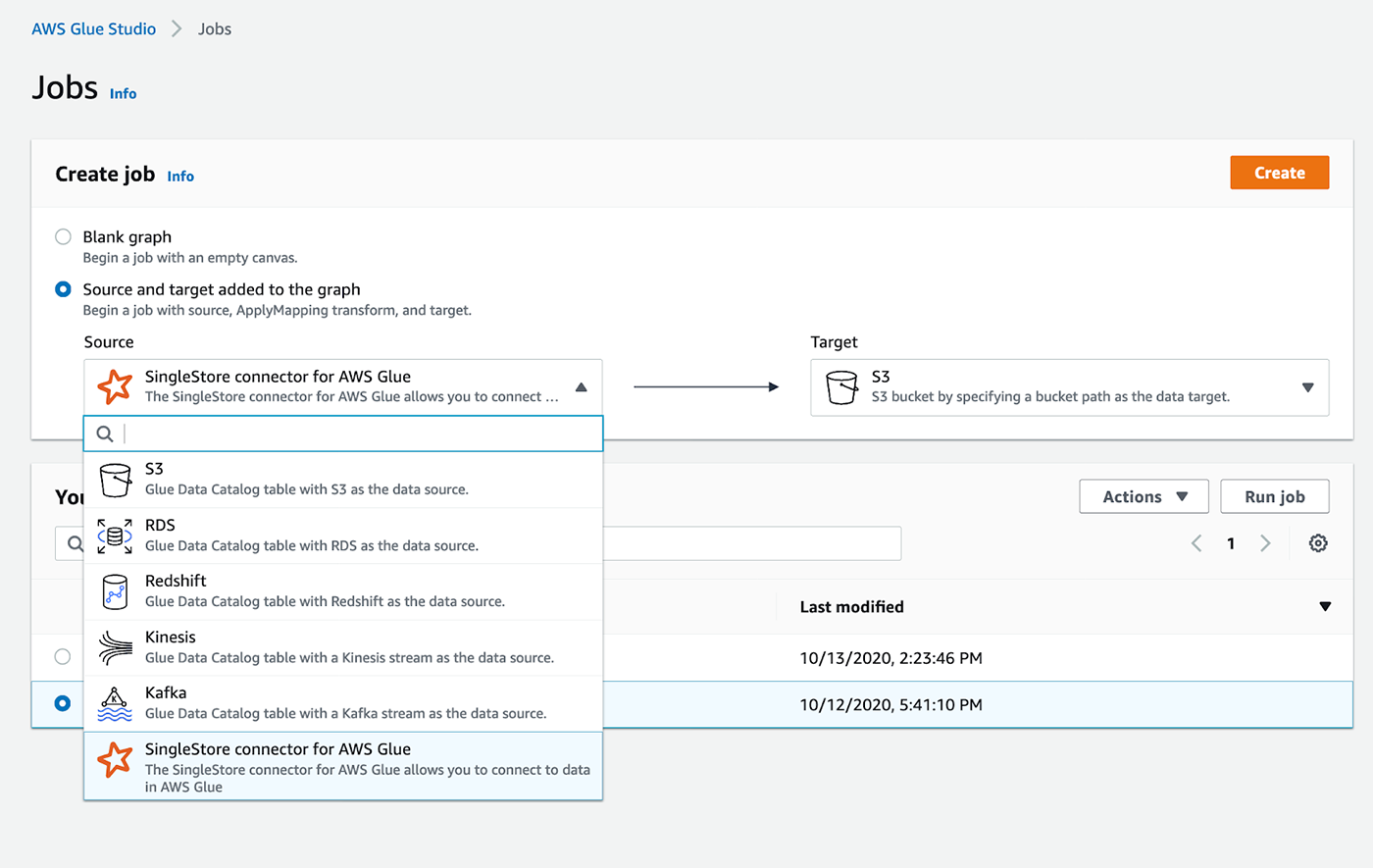
SingleStore is offering native support for AWS Glue, Amazon’s a serverless data preparation service. The latest integration enables developers, data engineers and data scientists to build SingleStore on Amazon Web Services more efficiently.
AWS Glue makes it easy for developers, data analysts, and data scientists to extract, clean, enrich, normalize, and load data. The fully managed, scaled-out Apache Spark environment for extract, transform, and load (ETL) jobs provided by AWS Glue matches well with SingleStore's distributed SQL design.
"SingleStore's R&D team leveraged AWS to deliver this high-performance, deep integration," said SingleStore Chief Product Officer Jordan Tigani. "This integration accelerates extract, transform, and load processes, and will delight data management professionals." This functionality works much the same way that SingleStore's Spark Connector delivers these benefits in other environments, Tigani added.
In this case, with SingleStore's deep integration leverages AWS Glue's fully managed, scaled-out Apache Spark environment for extract, transform and load (ETL) jobs. The combination of AWS Glue with SingleStore's distributed SQL design allows faster processing – thanks to parallel ingestion in AWS.
IDN asked Tigani to describe a few specific tasks or use cases where the SingleStore integration with AWS Glue removes complexity for developers and data professionals.
"Now that our SingleStore Spark Connector is seamlessly available in the AWS Glue Marketplace, developers - after a couple of clicks - can immediately start developing ETL routines instead of worrying about how to first integrate [AWS] Glue and SingleStore libraries," Tigani told IDN.
Moreover, SingleStore offers unique benefits to those working with Apache Spark, Tigani added. "Spark developers leveraging Python, Scala or Java in their AWS Glue ETL routines will be working with SingleStore tables as true Spark DataSources, speeding up their development cycles. When leveraged within AWS Glue ETL routines, applicable Spark dataframe operations get translated to true SQL, and are executed with high performance and excellent concurrency."
The latest support for AWS Glue comes on the heels of SingleStore's latest core update SingleStore 7.3.
SingleStore Simplifies Cloud Data; Unifies Workloads for Analytics & Operations
IDN also asked Tigani about his views on the trends emerging as enterprise adoption of cloud and hybrid architectures spur the deployment of more specialized datastores. SingleStore is responding to these trends with features to promote "ease of use, universal storage, performance and system of record," he said.
In detail, Tigani said:
The proliferation of special-purpose datastores is complicating cloud infrastructure, inflating cloud bills, and adding unnecessary latency in copying and moving data from multiple operational stores to analytical stores.
To tame the growing cloud complexity and data infrastructure sprawl, organizations should look to solutions like SingleStore that unify workloads across operational and analytical use cases without sacrificing the speed, scale, and flexibility which makes special-purpose datastores attractive. With fewer types of datastores and less data movement among them, data infrastructure is simplified and there are fewer skill sets to maintain, allowing you to focus on accelerating your business.
The SingleStore DB 7.3 release delivers a big advance in our ability to support system-of-record applications on SingleStore, including improvements to Universal Storage (upserts, default table type); replication status monitoring; easier Avro schema migrations; faster large joins; and more.
Major Features in SingleStore DB 7.3
The recently-released SingleStore 7.3 sports upgrades across multiple critical areas. In a blog post, head of SingleStore’s product management team Rick Negrin, listed several noted ones:
Universal Storage: The latest enhancements to SingleStore’s Universal Storage technology aim to support real-time analytics and online transaction processing (OLTP) on SingleStore – with high performance and low TCO (total cost of ownership).
Universal Storage is an extension of SingleStore’s columnstore technology that excels at analytics and improves OLTP, including support for indexes, unique keys, seeks, and fast, highly selective, nested-loop-style joins. With Universal Storage, data is highly compressed and doesn’t all have to fit in RAM.
Programmability: SingleStore supports the MPSQL language for programming internal extensions, including stored procedures and user-defined functions. The 7.3 release enhances this capability by providing additional flexibility for developers in these aspects:
Queries Use Less Memory: New functions and user-defined variables let queries use less memory. For example, A new JSON_AGG function takes a rowset with an arbitrary set of relationships and returns a single JSON object. Also, a set of user-defined variables are convenient for users building complex SQL scripts.
Flexibility for Developers: SingleStore DB now has DDL forwarding, which allows you to send both DDL and DML statements to any aggregator. This simplifies things for your developers so they don’t have to remember which endpoint to use based on the type of operation.
Cloud-Native Ingestion Enhancements: New enhancements for data ingestion that will be helpful for cloud deployments. Examples include:
- SELECT … INTO GCS allows users to load data from SingleStore DB into a Google Cloud Store bucket.
- A new configuration option multipart_chunk_size_mb allows users to load up to 5 TB of data per partition when running SELECT … INTO S3.
- SingleStore DB pipelines now integrate with Confluent schema registry, making it easy to add and remove fields from Avro schemas.
Greater Operations Visibility & Resilience: These improvements make SingleStore easier and more robust to operate and monitor. Among the updates:
- A new management view LMV_BACKUP_STATUS permits users to track the progress of a running backup along with the estimated time remaining.
- SingleStore DB lets you create resource pools for specifying resource limits so that non-critical workloads do not overwhelm your cluster. You can now run the BACKUP and RESTORE commands in resource pools to manage how much CPU they use.
Multi-way Join Efficiency Improvements: For queries that join more than 18 tables, the query optimizer generates plans more quickly and produces query plans that run faster.
The SingleStore Apache Spark integration will be available through the new AWS Glue Custom ETL Connectors feature, accessible on the AWS Glue console.
Related:
- Alluxio Empowers Data Architectures for Cloud-Scale and Multi-Tenant Projects
- Snorkel AI Boosts Success of AI Projects by Reducing Bottlenecks in Training Data
- SingleStoreDB Expands Capabilities for Real-Time Applications and Workloads
- Alteryx Adds AI/ML, Cloud Connectivity and More To Drive Self-Service Analytics
- Data Privacy and Fallacies
All rights reserved © 2025 Enterprise Integration News, Inc.