

InfluxData Time Series Update Ready To Change the Game for IoT, Analytics Apps 
InfluxData is shipping a major update to its open source time series data offering. IDN talks with vice president Tim Hall about InfluxDB 2.0, and how it makes it fast and easy to build and launch modern time-based apps.
by Vance McCarthy
Tags: database, Flux, InfluxData, ingest, query, store, templates, time series,

vice president of products

"With InfluxDB2.0 OSS developers can now ingest, query, store and visualize time series data in a single unified platform and use familiar skills."

InfluxData starts the New Year with a major update to its open source InfluxDB time series database offering.
Now in general availability, InfluxDB 2.0 OSS features a single unified platform, alongside new tools and integrations.
The latest upgrades aim to optimizing its time series platform for building IoT, analytics and monitoring applications – all of which depend on reliable time series data, Tim Hall, InfluxData’s vice president of products told IDN.
With the new update, “developers can now ingest, query, store and visualize time series data in a single unified platform, leverage new tools and integrations, and use familiar skills,” Hall said, IDN asked Hall to take us through some of InfluxDB 2.0’s more notable features and discuss a bit about trends he sees coming to time series apps in 2021.
In particular, InfluxData 2.0 looks to reduce the time and complexity developers face writing and managing such apps.
On that score, Hall called our attention to several notable InfluxDB 2.0 features.
Tops among them is the release of Flux, a user-friendly, functional query and programming language built specifically for time series data.
Flux aims to help developers more easily enrich and transform their data, as well as build forecasts, according to Hall. Flux can even help developers and app managers quickly identify anomalies and correlations, he added.
“Most developers working with time series data want to analyze large quantities of data,” Hall said. “This is in stark contrast to how developers tend to work with relational data or key-value pairs. Flux is designed to make the application of mathematical functions easy across time series data, and allows for the application of easy filtering to ensure that you are working with the specific ‘time series required.
Notably Flux is not limited to only working with time series, Hall added. This reflects emerging trends showing a more hybrid or heterogeneous profile of time series-sensitive apps.
“Flux also works with non-time series data,” Hall told IDN, and explained the reasons why. “Over the last five years, we’ve observed developers constantly trying to combine the results of their time series analysis with non-time series data. In the past, this required writing code, and if anything changed in either data set, required that code to be changed as well.
“Flux allows developers to query more than a dozen different SQL-based sources so they can easily combine relational data with time series data. This makes it easier to build applications quickly. Flux can be extended to support other sources as well and we’ll continue to expand on its capabilities,” Hall added.
Speaking of SQL, Hall also shared with IDN that InfluxData had made the on-ramp to Flux easier for millions of SQL users – not only developers, but even non-technical staff. Hall shared some details:
InfluxDB is a platform built with developers in mind and this extends to Flux as well. Flux is a functional scripting language and for developers familiar with languages like JavaScript. It’s designed to be highly readable and is very easy to get started quickly.
Here is a simple example:
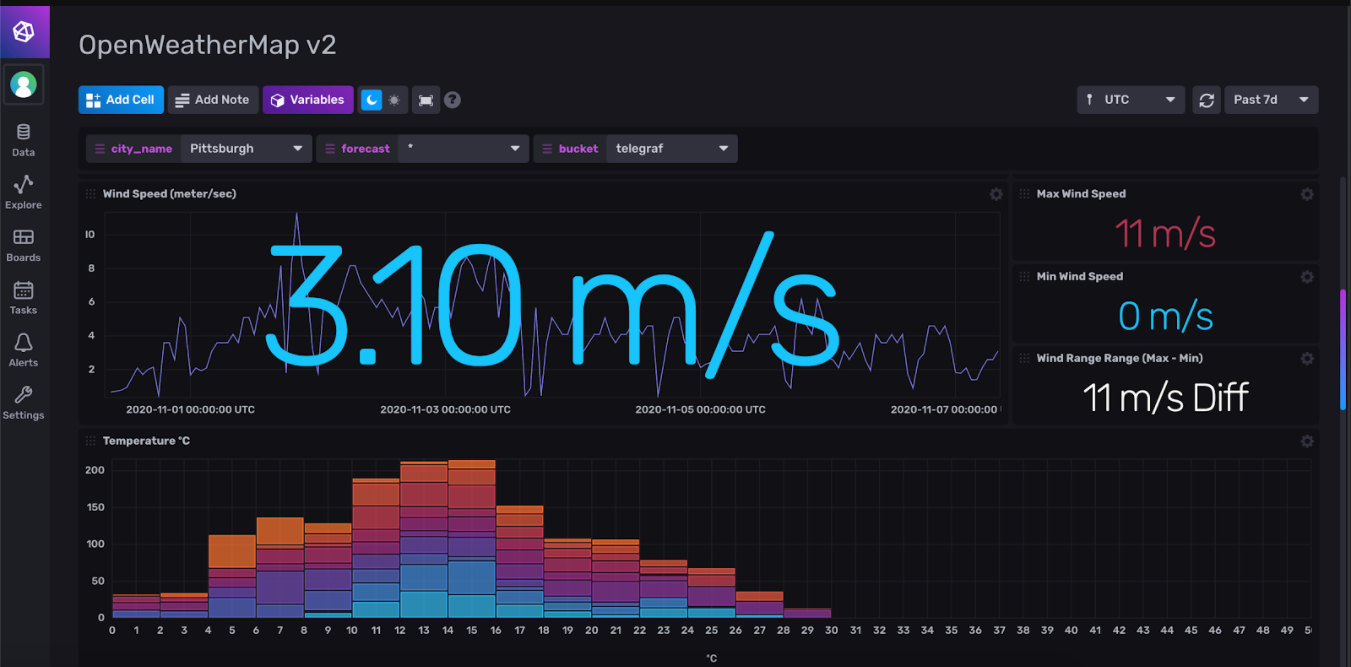
from(bucket:"telegraf")
|> range(start:-1h)
|> filter(fn: (r) => r._measurement == "foo")
|> exponentialMovingAverage(size:-10s)This Flux script uses the “bucket” named telegraf and looks at the data that has arrived in the last hour (-1h). It then filters the data down to all data points residing in measurement “foo.” Finally, it applies a function to all of the data which satisfies those criteria. In this case, resulting in an exponentialMovingAverage with a window size of 10s.
There are a few key concepts to understand, but once those are understood, Flux can be a very powerful and flexible language for working with data.
More Low-Code InfluxDB Templates for Quick Configuration
Another core update for InfluxDB 2.0 OSS is the expansion of their library of InfluxDB Templates. These are pre-packed ‘single-file monitoring configurations, which aim to cut down on the need for hand-coding and promote productivity. These templates contain a wide range of reusable solutions for everything from dashboards and Telegraf configurations to notifications and alerts in a single manifest file, Hall noted.
InfluxDB Templates are made up of multiple parts including configuration for data collection, dashboarding of collected metrics, alerts, tasks, and more, Hall said.
“The general idea is that developers who have expertise can contribute and easily share that expertise with others. There isn’t any secret sauce associated with, for example, server monitoring, so why not share best practices and techniques with others?,” he told IDN.
InfluxDB Templates cover a wide variety of use cases, including network monitoring, infrastructure monitoring, software monitoring and security monitoring.
There are currently 46 templates and half have been contributed by the community. The most popular templates are focused on some part of the hardware or software stack being used by a developer within his or her organization, Hall added.
InfluxDB 2.0’s time series database solution is built to handle the increasing types of high-volume, high-frequency data challenges of modern apps and infrastructure.
Hall also shared a real-world example of how developers can use InfluxDB Templates:
Let’s say I have a fleet of Linux servers and I want to gather their various metrics, including CPU utilization, memory, Disk IO, Swap usage, etc. By installing the Linux System Monitoring template, I immediately have: the configuration required to turn on all of these various metrics via Telegraf, and a dashboard to visualize all of this data.
The dashboard also comes with a filter that allows me to look at the various Linux servers by name. Deploying Telegraf with the pointer to the configuration is all that remains and as that rolls out (via automation tools such as Ansible, Puppet, or Chef), the metrics begin to flow back to InfluxDB and the dashboard populates. That’s it! I wrote no code, created no queries, etc. You are working with time series data and then can decide where you go from there.
For example, the focus could then shift towards creating alerts for problematic Linux servers.
One of the most common issues, still today, is running out of disk space.
Rather than spending time creating the basic dashboards and worrying about the configuration for the data collection, the developer can focus on building a threshold alert to be notified of any disk that exceeds 85% utilization. If they then want to add that to the template, they have the option to share it with the rest of the community.
Other Notable InfluxDB Updates; Analyst Views
InfluxDB OSS also added support for ‘client libraries,’ which includes the ability to write and query from popular languages. This onboard integration capability, Hall said, dramatically simplifies integration with other popular applications.
In turn, this helps avoid the bottlenecks that can frequently arise when time series apps need to communicate with outside resources. This ease-of-integration further empowers teams to leverage their existing programming language skills to build novel solutions, Hall noted.
Another upgrade to InfluxDB OSS is edge functionality, which adds the ability to aggregate and analyze time series data at the point of ingestion, which is where it’s most valuable to take action.
According to a recent analysts from IDC, the amount of data being produced is expected to grow exponentially from 45 zettabytes in 2019 to 175ZB in 2025. This explosion in data is expected primarily from applications, networks, containers, and an estimated 60 billion IoT devices.
“While there is a tremendous opportunity for organizations to leverage this data to enhance customer experiences, improve employee and process productivity, and to create competitive advantage, it will be challenging to store and analyze the large volumes and high-frequency streams of data,” the company stated. “These workloads will require rapid ingestion, advanced querying, and edge processing to maintain resource and cost efficiency, and maximize the value to end users. InfluxDB 2.0 is built to handle these data challenges of the future.”
New users can download and install InfluxDB 2.0 here, Current InfluxDB users can seamlessly upgrade from 1.x by downloading InfluxDB 2.0 and running a single command to transfer data.
InfluxDB 2.0 is licensed MIT License permissive — one of the most liberal open source licenses originating at the Massachusetts Institute of Technology.
Related:
- SolarWinds Brings “Resilience’ to IT Ops for Agentic AI and Autonomous Operations
- Tray Enterprise-Class AI Platform Casts Light on “Shadow MCP” and Controls “AI Sprawl”
- Xano 2.0 Updates Production Grade Backend for AI, Apps To Solve "Vibe Coding Trap"
- Ai4 2025 Vegas Wrap-Up: What Enterprises Need to Know About Emerging AI Solutions
- Boomi Agentstudio Looks To Deliver Full-Featured Management Platform for AI Agents
All rights reserved © 2025 Enterprise Integration News, Inc.