

Attunity Compose for Hive Automates Pipelines for Data Lakes; Speeds Up Moving from 'Raw Data' to 'Analytics-Ready’ 
Attunity is preparing a solution to speed and simplify how to make raw data more valuable to business. Attunity Compose for Hive will provide an automated data pipeline for delivering analytics-ready data into data lakes – quickly, continously and error-free. IDN speaks with Attunity’s Kevin Petrie.
by Vance McCarthy
Tags: ACID, analytics, Attunity, Compose, data lake, Hadoop, Hive, SQL, transform,

senior director for product marketing
"Many people view data lakes as a place to store a lot of raw data from a lot of sources. But a growing number want data to be more analytics-ready."

Data integration and big data management software solutions provider Attunity is continuing its mission to spur faster and easier ways to help companies create their own analytics-ready data lakes.
Now in beta, Attunity Compose for Hive brings automation, speed and intelligence to many tasks associated with taking data from ‘raw to ready’ for analytics and other business purposes, Kevin Petrie, senior director for product marketing at Attunity told IDN.
“Under the covers, we’re defining and automating a streamlined pipeline for data lakes. With these capabilities, we’re bringing consistency and integrity for high data volumes at high speed,” Petrie explained
One key innovation is Attunity’s ability to automatically create an update and transform data. These capabilities are new to the industry – not just Attunity, he added. Further, they can be performed on both the operational / historical data stores Attunity is creating.
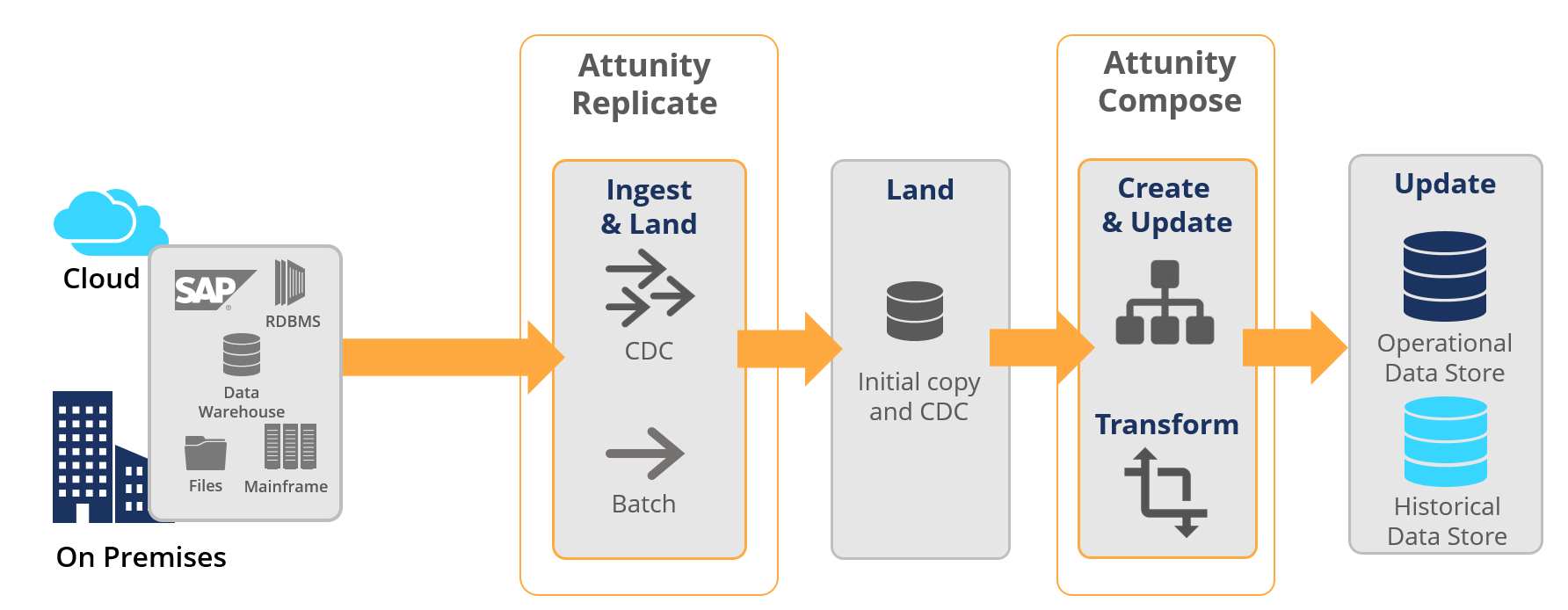
Attunity Compose for Hive supports a continuously updated data pipeline, with features for universal data ingestion, data structuring, transformation and data integrity. The capabilities span the data lifecycle, Petrie added, to support these crucial tasks
- ingest (in batch or real time) all major sources.
- copy data to landing zones in the cloud or on premises.
- create and generate Hive schema (for both operational and historical data stores).
- automatically apply necessary data transformations.
- continuously update Hive ACID (Atomicity, Consistency, Isolation, and Durability) Merge and
- support time-based partitioning to avoid bottlenecks from large data loads or getting hung up on partial (incomplete) transaction data.
While Hadoop users have an array of product choices for how to integrate data from hundreds – even thousands – of data sources into data lakes, “a big challenge today remains focused around structuring data for analytics,” he said. “A lot of Hadoop users appreciate the value of familiar SQL structures, ACID compliance and operational data stores but they still struggle when it comes to rapidly being able to use their data for analytics,” he added.
Attunity Says Automation, Data Pipelines Will Make Data Lakes More Analytics-Ready -- On a Continous Basis
“Many people view data lakes as a place to store a lot of raw data from a lot of sources, and gain economic storage and processing, but a growing number want their data to be more analytics-ready,” Petrie said. “That takes extra work.”
A key struggle companies have been having is laying an SQL-like structure ontop of Hadoop - and still be able to handle updates, insertions and deletions that won’t lock out users or impact business access, he explained.
This is where Attunity Compose for Hive is focused. Missing a solution that de-complicates, de-congests and de-conflicts data flow -- what Attunity calls “data pipelines" -- can cause real headaches for Hive users, Petrie said.
“You can get these bottlenecks when you are landing large transactional loads. And you can have an administrative burden of insuring that the operational data store you are creating within Hive is actually accurate and has transactional and data consistency,” Petrie told IDN.
Manual ETL coding is already a familiar burden. “But with Hive use cases, manual ETL can be increasingly hard (or even impossible) when you have updates coming in quickly across huge numbers of data sources," he added.
“Attunity Compose for Hive brings together a set of technologies to create SQL structures very quickly and automatically to optimize data lakes environment,” Petrie explained. He went on to share three (3) of its more noteworthy capabilities:
- Speed up analytics-ready data by automating the ability to create and continuously update both operational and historical systems of record,
- Ensure data consistency between source transactional systems and Hadoop Hive,
- Leverage the latest advanced SQL capabilities in Hive including new ACID Merge (available with Apache Hive 2.2 - part of Hortonworks 2.6).
“We’ve taken the notion of ETL automation to the next set of required tasks required to make raw data analytics-ready in Hive," he said. Underscoring the concept of the 'data pipeline,' Attunity Compose for Hive can integrate with Attunity Replicate to land data in Hadoop and then create target schemas (operational data stores and historical data stores) in Hive.
The two work together like this, Petrie explained.
Attunity Replicate will create an automated interface for ingesting and landing data in the data lake.
Attunity Compose for Hive will take the data, perform some transformations, as well as create and provide ongoing updates of schema for operational or historical data stores. "This is our fast way to deliver data lake analytics. [IDN asked if companies interested in Compose for Hive need to have Attunity Replicate. “They don’t need it. It is a large new advantage to current Attunity Replicate users but anyone can use Attunity Compose for Hive,” he said.]
Anotehr key aspect of this seamless automated is the ability to do continuous updates, Petrie said, adding, "This is critical.” To leverage all availabe technology for this task, Attunity partnered with core open source drivers or Hadoop and Hive, he said.
Apache Hive and Hortonworks 2.6 recently included an efficient way to create ACID-compliant data sets thanks to a new capability to process data insertions, updates and deletions in a single pass. "We collaborated with Hortonworks and we’re the first one to automate it. This came from conversations we had with our customers," he said.
To support hiccup-free continuous updates, Attunity Compose for Hive also adds “time-based partitioning,” he added, so transactions come in for a set time period (1 minute, for example). This assures only completed transactions are processed. Anything not completed waits for the next cycle
Putting all these capabilities together, Petrie paints the picture of a streamlined data pipeline – optimized for the need of analytics in Hadoop.
“Once the data has been landed in Hadoop by Attunity Replicate, Compose for Hive will automatically create schema structures for the operational data store and historical data store, transform data, move the data and continuously update it in those data stores,” Petrie said. “It’s a pipeline designed to quickly get [raw data] to analytics-readiness in the data lake.”
Attunity is already eyeing ways to bring such automations across other parts of teh daat pipeline, As Petrie put it, “Once you automate one piece in the chain, we can move onto the next."
Early adopters are already seeing some ROI from such an approach – not simply for speeding up how quickly they can run analytics against Hadoop / Hive data, but in several cases, how companies can tackle huge volume of data from many sources.
“We have customers working on huge data lake implementations and this is a step forward for them. In a lot of cases, we’re talking about 1 or a few large data lakes and the complexity comes from sources,” Petrie told IDN. One company is going to 4,000 sources using Attunity’s approach, he added.
At Verizon, execs are also intrigued. “We look forward to learning about the capabilities of Attunity Compose for Hive," said Arvind Rajagopalan, Director, Global Technology Services (GTS) at Verizon in a statement. "We are ingesting data in real-time with Attunity Replicate now. The new [Attunity] Compose offering has the potential to accelerate creation of operational and historical data stores on our Hortonworks Hadoop platform, which would provide our financial analysis and modeling teams with faster and deeper visibility into business line performance,” he added.
Attunity Compose for Hive is slated to ship by year’s end, Petrie said.
Related:
- SolarWinds Brings “Resilience’ to IT Ops for Agentic AI and Autonomous Operations
- Tray Enterprise-Class AI Platform Casts Light on “Shadow MCP” and Controls “AI Sprawl”
- Xano 2.0 Updates Production Grade Backend for AI, Apps To Solve "Vibe Coding Trap"
- Ai4 2025 Vegas Wrap-Up: What Enterprises Need to Know About Emerging AI Solutions
- Boomi Agentstudio Looks To Deliver Full-Featured Management Platform for AI Agents
All rights reserved © 2025 Enterprise Integration News, Inc.